On June 9, 2026, Anthropic did something it had never done before: it released a single frontier model as two separate products. Meet Claude Fable 5 — the most capable AI model the company has ever made broadly available — and its locked-down twin, Claude Mythos 5.
If you've been following the Claude lineup of Opus, Sonnet, and Haiku, this launch breaks the pattern in a way worth understanding. Here's what actually changed, what the benchmarks say, and what it means for the people who build with these models.
The headline: a brand-new model tier
For over two years, Claude came in three flavors — Opus (most capable), Sonnet (balanced), and Haiku (fastest). That structure has held since Claude 3 arrived in March 2024.
Fable 5 introduces the first new tier since then: the Mythos class, which sits above Opus in raw capability. Anthropic describes Fable 5 as "state-of-the-art on nearly all tested benchmarks," with one consistent theme:
The longer and more complex the task, the larger Fable 5's lead over every other model.
This is the key mental model. Fable 5 isn't built to win at quick Q&A — Opus 4.8 is still a perfectly good default there. Fable 5 is built for long-horizon, autonomous work: multi-hour coding migrations, deep research, multi-step agentic pipelines.
Why two models? The safety split explained
This is the part most coverage glosses over, and it's the most interesting story.
The underlying model is so capable in sensitive domains — especially cybersecurity and biology — that Anthropic previously deemed the raw version too dangerous to release publicly. So instead of holding it back entirely, they split it into two.
Claude Fable 5 is generally available to everyone. It runs with safety classifiers active, and it's aimed at the general public, builders, and enterprises.
Claude Mythos 5 is the exact same underlying model, but with the safeguards lifted in some areas. Access is restricted to vetted partners through Project Glasswing — primarily cyberdefense and infrastructure providers, and soon a small set of biology researchers.
Here's how the safeguards work in practice: Fable 5 runs a set of classifiers that watch for queries touching cybersecurity, biology/chemistry, or model distillation. When one trips, the request is automatically handled by Claude Opus 4.8 instead — and you're told when it happens.
The clever part is that this isn't a hard refusal. A fallback to Opus 4.8 (itself a strong model) is a much better user experience than a flat "I can't help with that." And according to Anthropic's data, more than 95% of Fable sessions never trigger a fallback at all — meaning for the vast majority of work, you're getting the full Mythos-class model.
One detail buried in the footnotes: "Fable" comes from the Latin fabula ("that which is told"), echoing the Greek mythos. The safeguards are literally the only thing separating the two names.
The benchmarks: where Fable 5 pulls ahead
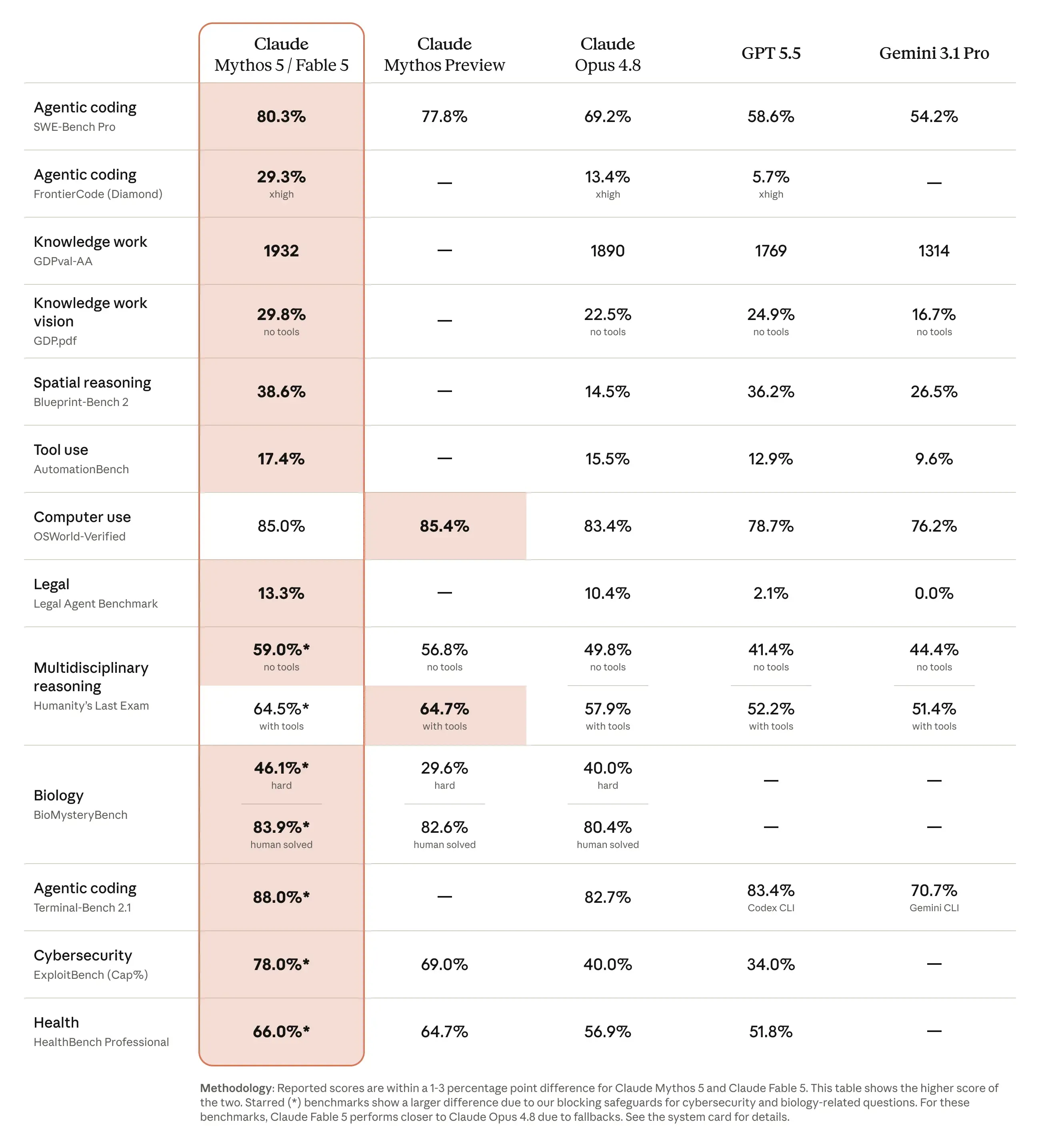
The numbers back up the "longer task = bigger lead" framing. A few standouts, with Fable 5's score first, compared against the field:
SWE-Bench Pro (agentic coding): Fable 5 hits 80.3%, versus 69.2% for Opus 4.8, 58.6% for GPT-5.5, and 54.2% for Gemini 3.1 Pro.
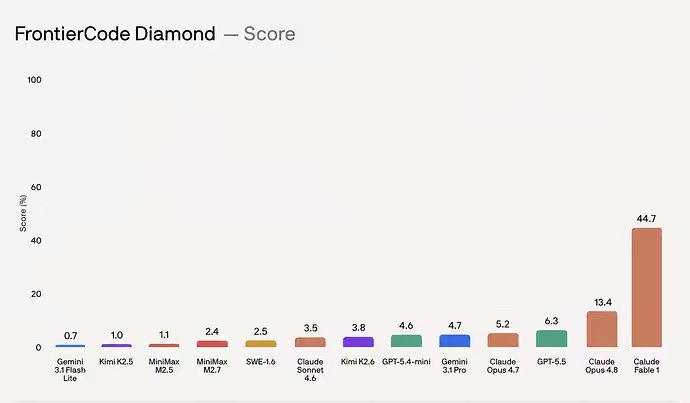
FrontierCode (Diamond, xhigh): Fable 5 reaches 29.3% — more than double Opus 4.8's 13.4%, and far ahead of GPT-5.5 at 5.7%.
Terminal-Bench 2.1: Fable 5 scores 88.0%, edging out GPT-5.5 (83.4%) and Opus 4.8 (82.7%).
GDPval-AA (knowledge work, ELO): Fable 5 leads at 1932, ahead of Opus 4.8 (1890), GPT-5.5 (1769), and Gemini 3.1 Pro (1314).
The gap is widest on hard, long-horizon coding — FrontierCode roughly doubles Opus 4.8. On short, well-scoped tasks, the two are much closer, which is exactly why Opus 4.8 remains the sensible default for routine production traffic.
The capabilities that actually impress
Benchmarks are one thing. The real-world demos are more telling.
Software engineering. Stripe reported that Fable 5 performed a codebase-wide migration on a 50-million-line Ruby codebase in a single day — work that would have taken a full team over two months by hand.
Vision. Fable 5 can rebuild a web app's source code from screenshots alone, and it beat Pokémon FireRed using only raw game screenshots — no maps, no navigation aids, no helper harness. Earlier Claude models needed an elaborate scaffold just to play.
Memory and long-context. With a 1-million-token context window and persistent file-based memory, Fable 5 stays coherent across millions of tokens. In a test playing Slay the Spire, persistent memory boosted its performance three times more than it did for Opus 4.8.
Science (via Mythos 5). The unrestricted twin accelerated parts of a drug-design process roughly 10×, and produced novel molecular-biology hypotheses that human scientists preferred about 80% of the time in blind comparisons.
What this means if you build with Claude
A few practical things to know before you switch your stack over.
It's not the default — you have to opt in. The API model ID is claude-fable-5. In Claude Code, you select it with /model fable. It's available from day one on the Claude API, Amazon Bedrock, Google Vertex AI, Microsoft Foundry, and GitHub Copilot.
Thinking is always on. You can't disable the thinking parameter on Mythos-class models. Instead, you control reasoning depth via the effort parameter. At the highest effort, Fable 5 reflects on and validates its own work — which is what makes hands-off autonomous operations viable.
It's roughly 2× the price of Opus 4.8. Fable 5 costs $10 per million input tokens and $50 per million output tokens. Opus 4.8, by comparison, is $5 per million input and $25 per million output. The smart play most teams are landing on is to route by task: send the hard, long-running jobs to Fable 5, and keep everyday work on Opus 4.8. A new fallbacks API parameter (beta) makes this kind of routing easier.
There's a new 30-day data retention requirement. To operate the safety classifiers, all traffic on Mythos-class models is retained for 30 days. Anthropic says it won't be used for training or any non-safety purpose, and is deleted afterward — but if you handle sensitive data, factor this in.
Subscription access is rolling out in stages. Fable 5 is free on Pro, Max, Team, and seat-based Enterprise plans through June 22. After June 23 it requires usage credits, until capacity allows Anthropic to make it standard.
The bigger picture
What makes this launch notable isn't just a higher benchmark score. It's the deployment philosophy: Anthropic took a model it considered genuinely dangerous and, rather than shelving it or releasing it wholesale, engineered a way to ship its benefits to everyone while keeping the riskiest capabilities behind a vetted-access wall.
Whether that "split the frontier in two" approach becomes the industry norm — or just an Anthropic quirk — is the question worth watching over the next year. For now, Fable 5 is the most powerful model you can actually put your hands on, and the gap it opens on long, complex work is real.
If your workload involves multi-hour agentic tasks, large-codebase reasoning, or document-heavy analysis, it's worth the test drive. For everything else, Opus 4.8 is still right there.