
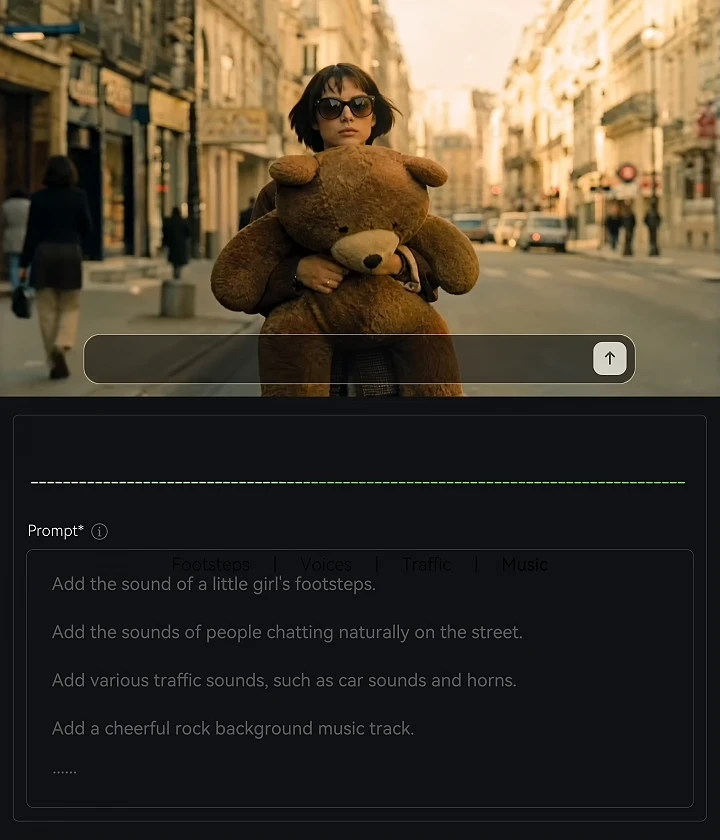
AI Music
Generate background music, hooks, intros, and emotional beds for video scenes.
Prompt
Create a warm, nostalgic Nordic instrumental: slow upright piano, deep cello, and a gentle fading finish.
Audio Case
Nordic Piano and Cello
0:370:00
Powered by ByteDance's Seed Audio 1.0 — a multimodal audio director that generates dialogue, music, sound effects, and ambience in one pass. Use text, reference audio, or images for zero-shot voice control and broadcast-ready scenes.
Go beyond basic TTS: turn one prompt into a fully mixed audio scene with multi-speaker dialogue, emotional delivery, background music, and foley — powered by multimodal inputs.
Generate background music, hooks, intros, and emotional beds for video scenes.
Create a warm, nostalgic Nordic instrumental: slow upright piano, deep cello, and a gentle fading finish.

Generate natural, multilingual narration for ads, tutorials, product demos, and explainers. Switch languages to hear the same scene in English, Chinese, Japanese, Korean, French, German, and more.
Create a nostalgic night-train scene with rail clatter and window wind. Dialogue between a homesick male passenger and a warm attendant. Man: "Two more hours to go. I wonder if the old locust tree at home has blossomed this year." Attendant: "Going home for the new year, young man? This train may be slow, but it'll get you home safe and sound."
Listen to the same scene in multiple languages:

Reuse a recognizable brand, creator, or spokesperson voice across campaign variants.
Using Audio1's voice, narrate a short ancient-forest line about stillness, leaves, wind, and returning to the beginning.

Create product sounds, ambience, transitions, UI cues, and cinematic detail.
Generate a 10-second soda pour: crisp ice in glass, fizzy bubbles, liquid over ice, then a soft final clink.
Create ready-to-use audio for ads, UGC scenes, product demos, lessons, podcasts, and brand voice campaigns.

Generate hook voiceovers, background music, product sounds, and a final CTA for TikTok, Reels, Shorts, and paid social.
Generate the full audio layer for videos with one model built for speech, music, effects, and voice cloning.
Create music, speech, dialogue, sound effects, and cloned voice reads from one production prompt.
Script, mood, timing, speaker roles, and sound details.
Ready-to-edit audio for ads, demos, courses, podcasts, and brand campaigns.
Use the same workflow whether you need a short ad read, a two-speaker scene, a music bed, or a branded voice variant.
Describe the full scene once, including timing, mood, speaker roles, music, and sound details.
Generate background beds, hooks, intros, and emotional instrumentals for video scenes.
Create narration, customer conversations, avatar reads, and two-speaker UGC exchanges with natural pacing.
Add product sounds, ambience, transitions, UI cues, and cinematic details.
Reuse a reference voice across offers, demos, regions, and recurring brand content.
Tell the AI what to say, how it should feel, and what sounds to include.
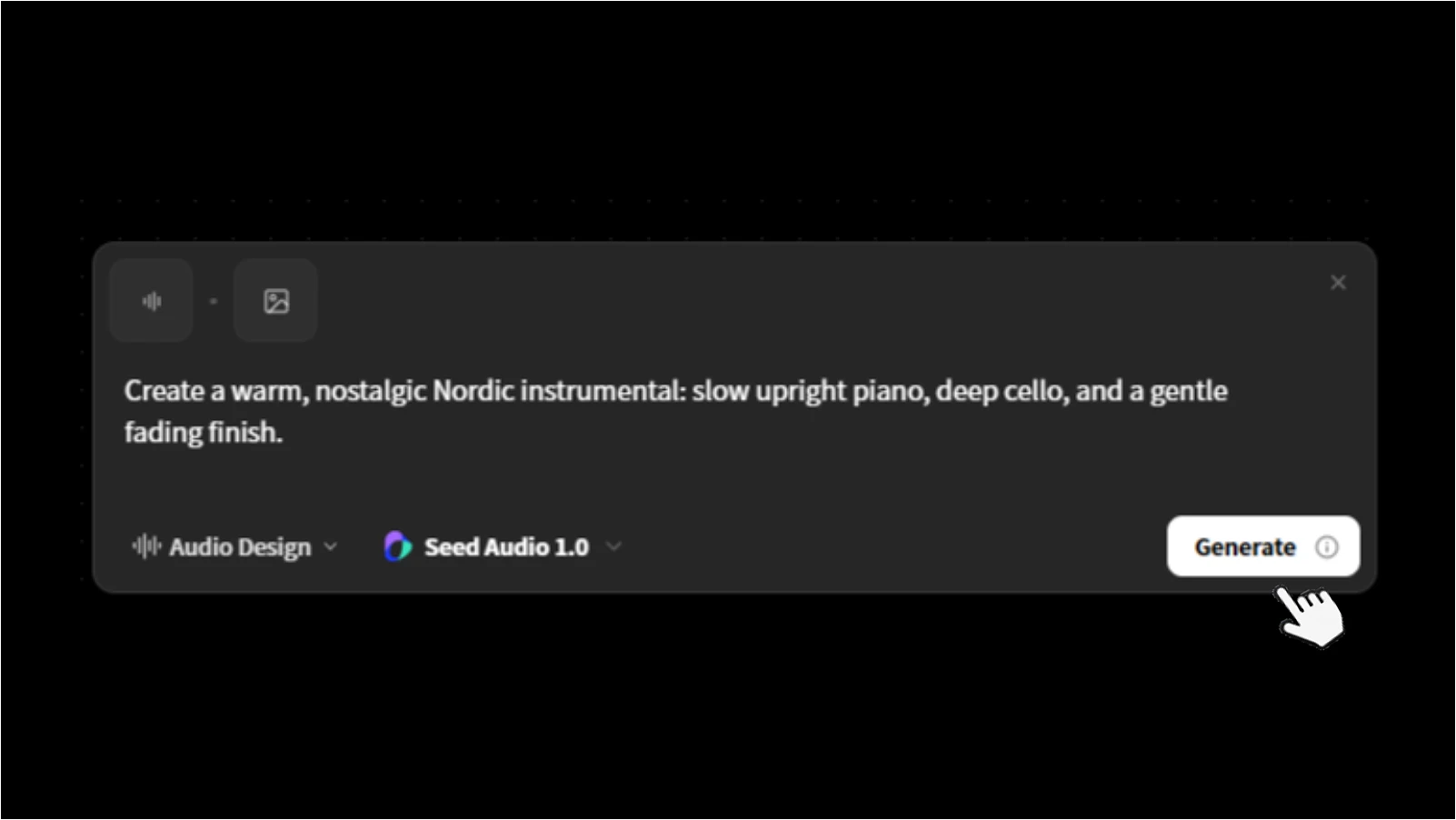
Topview creates speech, music, dialogue, and effects in one pass.
Export a clean MP3 file when the generated audio is ready.
Create speech, music, dialogue, and sound effects for your next video.